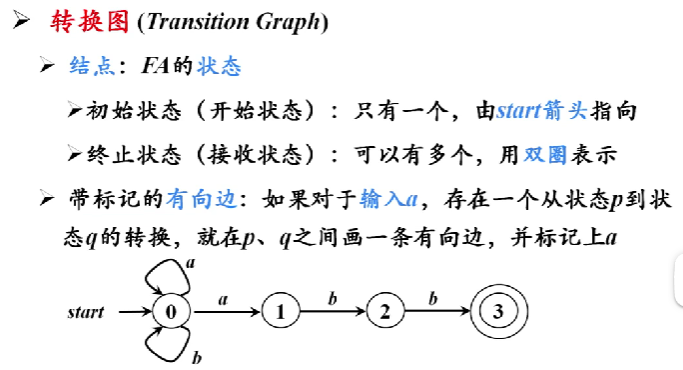
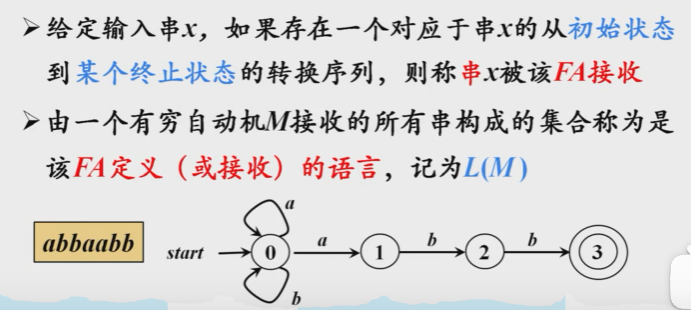
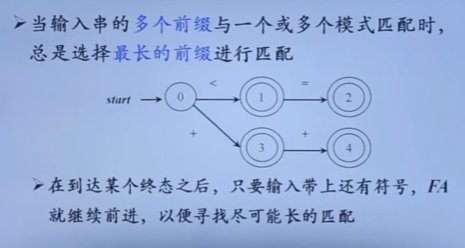
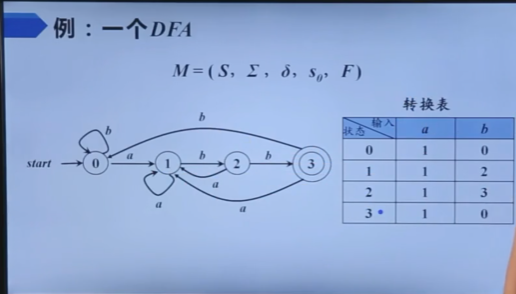
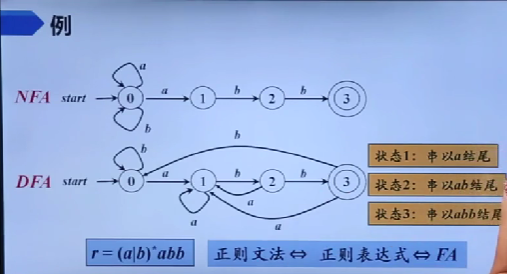
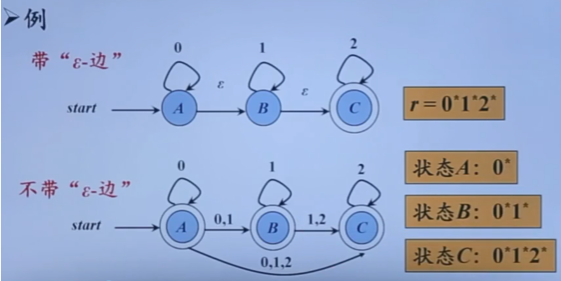
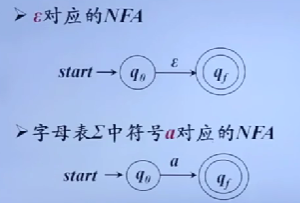
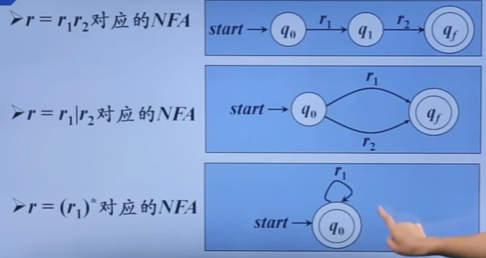
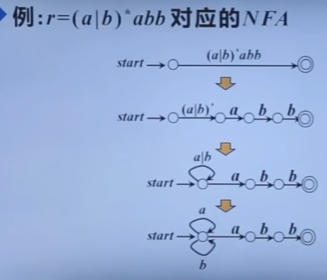
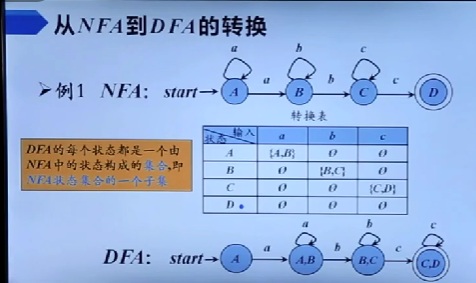
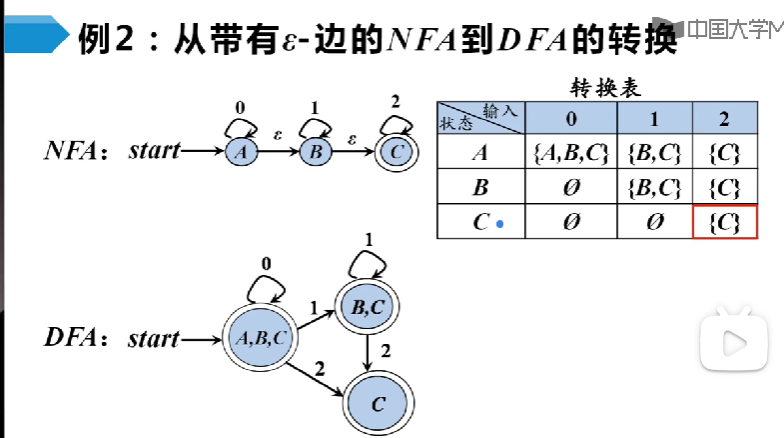
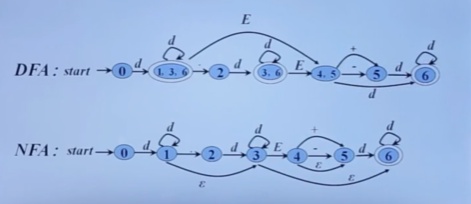
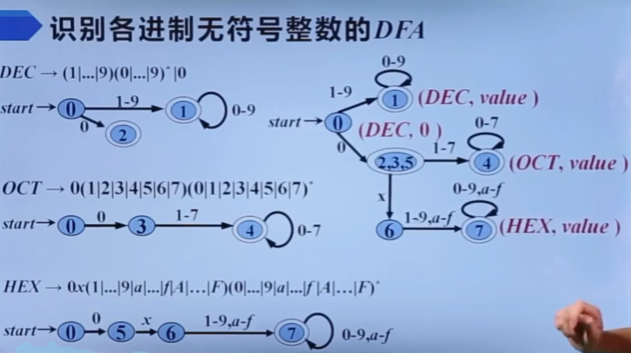
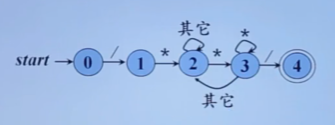
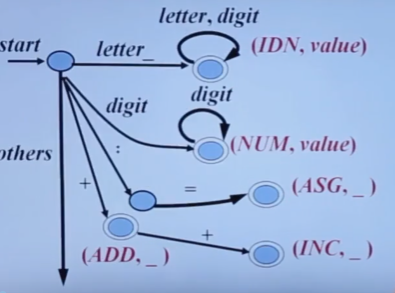
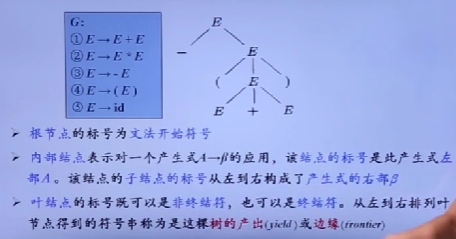
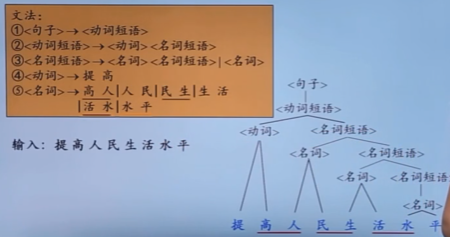
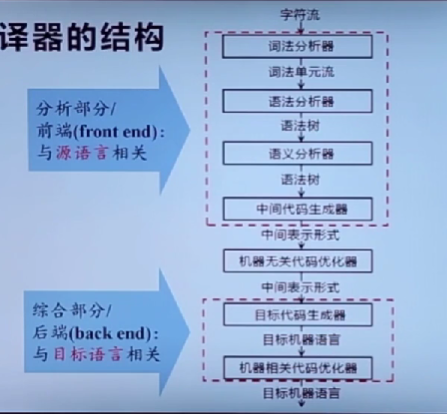
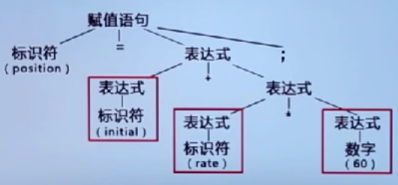
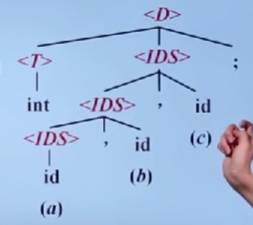
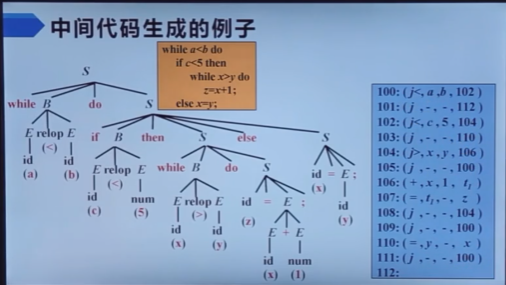
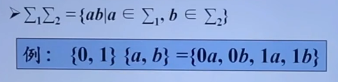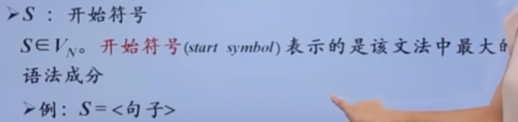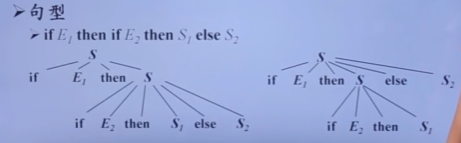自顶向下的分析
- 从分析树的顶部(根节点)向底部(叶节点)方向构造分析树
- 可以看成从文法开始符号S推导出词串w的过程
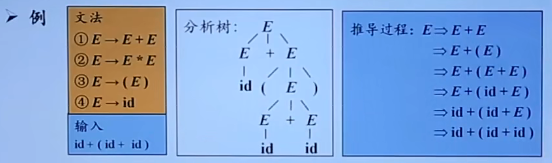
- 在每一步推导中,都需要做两个选择
- 替换当前句型中哪一个非终结符
- 用该非终结符的哪一个候选式进行替换
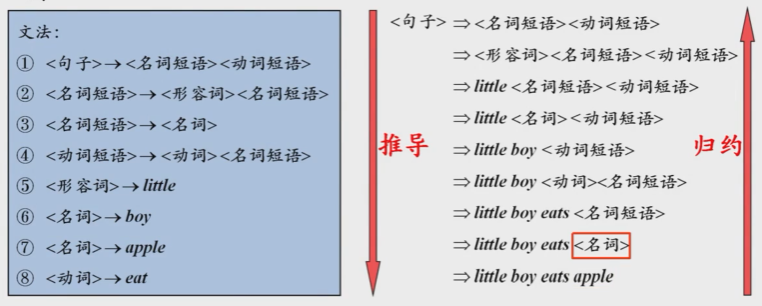
最左推导
在最左推导中,总是选择每个句型的最左非终结符进行替换
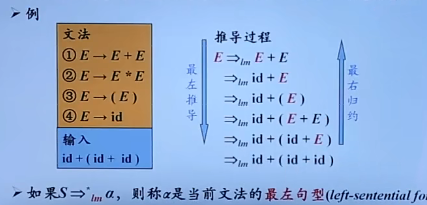
最右归约过程是最左推导的逆过程。
最右推导
最右推导,总是选择每个句型的最右非终结符进行替换

最左推导和最右推导的唯一性
在推导的过程中,可以选择不同的非终结符,因此推导不一定具备唯一性。
但是最左推导和最右推导总是选择最左或者最右的非终结符进行推导,因此最左推导和最右推导是唯一的。
由于分析器总是自左向右扫描字串,因此自顶向下的语法分析总是最左推导。
这个连接讲的非常清楚,可以直接看视频。
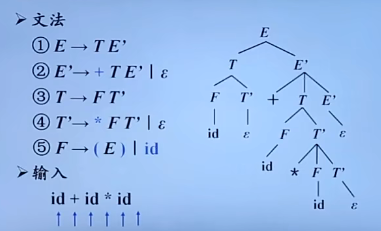
自顶向下语法分析的通用形式

预测分析

文法转换
不是所有文法适合自定线下分析
问题1

匹配abc的第一个a的时候,有两个可能的候选项。
问题2

左递归文法会使得递归下降分析器陷入无限循环。因此需要消除左递归
消除直接左递归

消除间接左递归

把S的定义带入到下面的S中,转换成直接左递归的形式,再用直接左递归的消除方法来消除直接左递归。
提取左公因子
文法中的某个符号的多个候选式存在公共前缀的情况

消除左递归和回溯的方法(※)
LL(1)文法
递归下降分析会遇到回溯,会影响效率,如果能预测每一步,就可以避免回溯。LL(1)文法可以使用预测分析技术。
S_文法


在上面的例子中,有两个输入字串,第一个使用空产生式没问题,第二个就有问题。但是不是所有都能使用。

非终结符的后继符号集

产生式的可选集

串首终结符集

写成=>*指可以通过n步推导出来,n可以为0
LL(1)文法

由于LL(1)文法中同一非终结符的各个候选式的SELECT集互不相交,因此可以构造预测分析器
- 第一个L表示的是从左向右扫描输入
- 第二个L表示的是产生最左推导
- “1”表示在每一步中只需要向前看一个输入符号来决定一个输入符号来决定语法分析动作
FIRST集和FOLLOW集的计算
计算(一个)符号X的FIRST(X)
FIRST(X):可以从X推导出的所有串首终结符构成的集合
如果X=>*ε,那么ε∈FIRST(X)
先看一个例子,注意概念抽象,例子需要着重理解

需要着重理解非终结符的FIRST集的含义。其实就是说这个非终结符能够推导出什么终结符,它们的集合就是FIRST集。如果推导出的是非终结符,那么就和推导出的第一个非终结符的FIRST集相同。
计算串的FIRST集

就是加入最左的一个非终结符的FIRST集合,但是如果这个非终结符可以推导出ε的话,那么就考虑它右边的非终结符。
计算非终结符A的FOLLOW(A)
FOLLOW(A):可能在耨个句型中紧跟在A后面的终结符的集合
如果A是某个句型的最右符号,那么将结束符“$”加入到FOLLOW(A)中
文法的开始符号本身就是一个句型,所以需要把$加入到开始符号的FOLLOW集中。同时终结符是不考虑空串ε的,所以第一个产生式的T后面跟了E‘,因此T的FOLLOW中应该有E’的FIRST集中的终结符(不包括ε)
这一讲比较难理解,建议看看视频理解
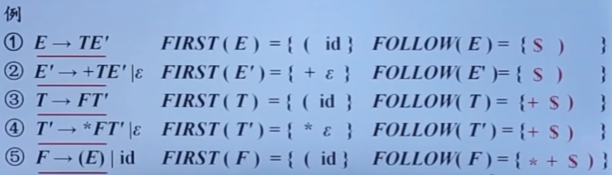
算法如下

这个算法最好在理解的基础上记忆,最好的办法就是能够做一个例题。
例:表达式文法各产生式的SELECT集

第(2)个表达式和第(3)个表达式有相同的左部E‘,但是它们的SELECT集不相交,第(5)个表达式和第(6)个表达式也是如此。因此上面的文法是LL(1)文法。构造预测分析表如下
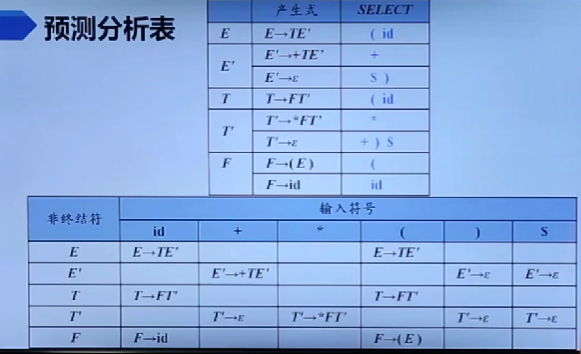
LL(1)文法的分析方法
- 递归的预测分析法
- 非递归的预测分析法
递归的预测分析法
递归的预测分析法是指:在递归下降分析中,编写每一个非终结符对应的过程的时候,根据预测分析表进行产生式的选择