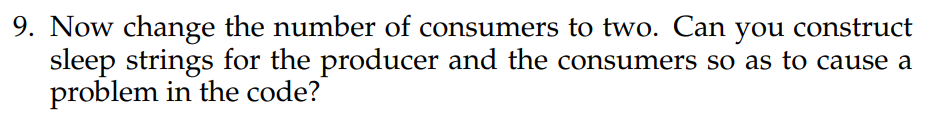操作系统第三部分作业 作业范围
第26章1、2、3、4题
第28章1、2、3、4、5、6、7题
第30章1、2、4、8、9、10、11题
第31章1、2、4、5、6题
第26章 1. 首先查看这个程序,得到结果如下
1 2 3 4 5 6 7 8 9 sh> cat loop.s .main .top sub $1 ,%dx test $0 ,%dx jgte .top halt
现在我们理解了loop.s句子的含义。现在我们看看题目,假设dx的初始值是0,很快就可以计算出每个指令执行的时候dx的值。
1 2 3 4 5 6 7 8 $ ./x86.py -p loop.s -t 1 -i 100 -R dx ... dx Thread 0 0 -1 1000 sub $1 ,%dx -1 1001 test $0 ,%dx -1 1002 jgte .top -1 1003 halt
dx作为循环变量判断是否跳出循环,上述语句可以写成c语言的语句如下:
1 2 3 4 int i = n;while (i >= 0 ) { i--; }
所以它的价值就在于循环递减变量以及循环变量判断是否跳出循环。
2. 现在运行相同的代码,但是使用如下标志,但是设定了寄存器的初始值如-a后面所赋值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 $ ./x86.py -p loop.s -t 2 -i 100 -a dx=3,dx=3 -R dx ... dx Thread 0 Thread 1 3 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 1 1000 sub $1 ,%dx 1 1001 test $0 ,%dx 1 1002 jgte .top 0 1000 sub $1 ,%dx 0 1001 test $0 ,%dx 0 1002 jgte .top -1 1000 sub $1 ,%dx -1 1001 test $0 ,%dx -1 1002 jgte .top -1 1003 halt 3 ----- Halt;Switch ----- ----- Halt;Switch ----- 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 1 1000 sub $1 ,%dx 1 1001 test $0 ,%dx 1 1002 jgte .top 0 1000 sub $1 ,%dx 0 1001 test $0 ,%dx 0 1002 jgte .top -1 1000 sub $1 ,%dx -1 1001 test $0 ,%dx -1 1002 jgte .top -1 1003 halt
在这种情况下,多线程不会影响结果的运行,因为两个线程执行的时候不是共享同一个edx的。这种情况下,两个线程只使用自己的dx的值,dx在每个线程从3到-1。并且在中断前halt跳出循环。
至于这段代码是否有竞态条件?首先要弄清楚什么叫竞态条件等两个基本概念。
临界区:访问共享资源的一段代码,资源通常是一个变量或数据结构。
竞态条件:出现在多个执行线程同时进入临界区时,他们都试图更新共享的数据结构导致了不确定结果
这一段loop.s中对共享资源更新的部分的代码就是sub指令这一条。因此因此我们可以看临界区就是这一段loop.s或者就是sub这一句。很明显从在这种情况下,线程每100条指令中断1次,而还没到100条指令就已经跳出循环了。这种情况下可以看出来,两段代码是没有竞态条件的。
3. 这一组测试使得中断间隔非常小而且随机,使用不同的种子-s查看不同的交替。中断频率是否会改变这个程序的行为。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 $ ./x86.py -p loop.s -t 2 -i 3 -r -a dx=3,dx=3 -R dx ... dx Thread 0 Thread 1 3 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 3 ------ Interrupt ------ ------ Interrupt ------ 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 2 ------ Interrupt ------ ------ Interrupt ------ 1 1000 sub $1 ,%dx 1 1001 test $0 ,%dx 2 ------ Interrupt ------ ------ Interrupt ------ 1 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 1 1002 jgte .top 0 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 1 1001 test $0 ,%dx 1 1002 jgte .top 0 ------ Interrupt ------ ------ Interrupt ------ 0 1001 test $0 ,%dx 0 1002 jgte .top -1 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 0 1000 sub $1 ,%dx -1 ------ Interrupt ------ ------ Interrupt ------ -1 1001 test $0 ,%dx -1 1002 jgte .top 0 ------ Interrupt ------ ------ Interrupt ------ 0 1001 test $0 ,%dx 0 1002 jgte .top -1 ------ Interrupt ------ ------ Interrupt ------ -1 1003 halt 0 ----- Halt;Switch ----- ----- Halt;Switch ----- -1 1000 sub $1 ,%dx -1 1001 test $0 ,%dx -1 ------ Interrupt ------ ------ Interrupt ------ -1 1002 jgte .top -1 1003 halt
再看看不同的随机种子下是什么样的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 $ ./x86.py -p loop.s -t 2 -i 3 -r -a dx=3,dx=3 -R dx -c -s 1 ... dx Thread 0 Thread 1 3 2 1000 sub $1 ,%dx 3 ------ Interrupt ------ ------ Interrupt ------ 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 2 ------ Interrupt ------ ------ Interrupt ------ 2 1001 test $0 ,%dx 2 1002 jgte .top 1 1000 sub $1 ,%dx 2 ------ Interrupt ------ ------ Interrupt ------ 1 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 1 1001 test $0 ,%dx 1 1002 jgte .top 1 ------ Interrupt ------ ------ Interrupt ------ 1 1001 test $0 ,%dx 1 1002 jgte .top 1 ------ Interrupt ------ ------ Interrupt ------ 0 1000 sub $1 ,%dx 0 1001 test $0 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 0 1000 sub $1 ,%dx 0 1001 test $0 ,%dx 0 1002 jgte .top 0 ------ Interrupt ------ ------ Interrupt ------ 0 1002 jgte .top 0 ------ Interrupt ------ ------ Interrupt ------ -1 1000 sub $1 ,%dx 0 ------ Interrupt ------ ------ Interrupt ------ -1 1000 sub $1 ,%dx -1 1001 test $0 ,%dx -1 1002 jgte .top -1 ------ Interrupt ------ ------ Interrupt ------ -1 1001 test $0 ,%dx -1 1002 jgte .top -1 ------ Interrupt ------ ------ Interrupt ------ -1 1003 halt -1 ----- Halt;Switch ----- ----- Halt;Switch ----- -1 1003 halt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 ./x86.py -p loop.s -t 2 -i 3 -r -a dx=3,dx=3 -R dx -c -s 2 ... dx Thread 0 Thread 1 3 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 3 ------ Interrupt ------ ------ Interrupt ------ 2 1000 sub $1 ,%dx 2 1001 test $0 ,%dx 2 1002 jgte .top 2 ------ Interrupt ------ ------ Interrupt ------ 1 1000 sub $1 ,%dx 2 ------ Interrupt ------ ------ Interrupt ------ 1 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 1 1001 test $0 ,%dx 1 1002 jgte .top 0 1000 sub $1 ,%dx 1 ------ Interrupt ------ ------ Interrupt ------ 1 1001 test $0 ,%dx 1 1002 jgte .top 0 1000 sub $1 ,%dx 0 ------ Interrupt ------ ------ Interrupt ------ 0 1001 test $0 ,%dx 0 1002 jgte .top -1 1000 sub $1 ,%dx 0 ------ Interrupt ------ ------ Interrupt ------ 0 1001 test $0 ,%dx -1 ------ Interrupt ------ ------ Interrupt ------ -1 1001 test $0 ,%dx -1 1002 jgte .top 0 ------ Interrupt ------ ------ Interrupt ------ 0 1002 jgte .top -1 1000 sub $1 ,%dx -1 ------ Interrupt ------ ------ Interrupt ------ -1 1003 halt -1 ----- Halt;Switch ----- ----- Halt;Switch ----- -1 1001 test $0 ,%dx -1 ------ Interrupt ------ ------ Interrupt ------ -1 1002 jgte .top -1 ------ Interrupt ------ ------ Interrupt ------ -1 1003 halt
总体看来,两个线程仍然是执行了从3到-1的循环操作,但是由于中断具有随机性,因此也就不能够确定什么时候执行完毕。从工作执行总量上看没有发生改变,但就工作执行的先后以及连续性上,改变了行为。
4. 第四题是访问一个公共变量而不是寄存器,在前面3题中,每个线程都有自己的专属寄存器。在中断的时候,线程的寄存器会保存,在恢复中断恢复的时候寄存器的值会被恢复。因此在循环上不会被破坏。但是现在的公共资源是一个变量,这可能引起某些变化。具体见下面。
首先看看这个程序looping-race-nolock.s是什么意思
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ cat looping-race-nolock.s # assumes %bx has loop count in it .main .top # critical section 临界区 mov 2000, %ax # get 'value' at address 2000 add $1, %ax # increment it: ax += 1 mov %ax, 2000 # store it back # see if we're still looping sub $1, %bx test $0, %bx jgt .top halt
可以看出来bx是循环变量,要对ax进行加一操作,可以写出程序的c语言表达如下
1 2 3 4 5 6 7 8 int i = n;int x;int *p;while (i >= 0 ) { *p = x; *p--; i--; }
然后我们再来看看下面这段执行情况。显然除了mov %ax 2000这个语句会更新2000地址的变量x的值,其余时刻都不会更新。因此结果如下。
1 2 3 4 5 6 7 8 9 10 11 $ ./x86.py -p looping-race-nolock.s -t 1 -M 2000 ... 2000 Thread 0 0 0 1000 mov 2000, %ax 0 1001 add $1 , %ax 1 1002 mov %ax, 2000 1 1003 sub $1 , %bx 1 1004 test $0 , %bx 1 1005 jgt .top 1 1006 halt
第28章 这一章的习题同样是一个用python写的x86模拟器,它能够运行.s格式的文件。
在这里,我们有四个常用的寄存器ax、bx、cx、dx,还有一个程序计数器PC。还有足够小但是能够满足我们需求的汇编指令。我们也加了一些额外的寄存器,例如ex和fx,这不见得能够与x86是对应的。但是这并没有什么问题。
1. 这题要我们用./x86运行flag.s文件。首先理解一下flag.s到底说了什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ cat flag.s .var flag .var count .main .top .acquire mov flag, %ax test $0 , %ax jne .acquire mov $1 , flag mov count, %ax add $1 , %ax mov %ax, count mov $0 , flag sub $1 , %bx test $0 , %bxjgt .top halt
上面这部分汇编代码其实很好理解,根据上面的注释,我们可以写出c语言版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 typedef char mutex_t ;mutex_t flag = 0x0 ;int count = 0 ;int i = n;int mian () { do { while (flag != 0x0 ) ; flag = 0x1 ; count++; flag = 0x0 ; i--; } while (i > 0 ); exit (1 ); }
所以flag.s的功能就是在循环变量被减到0之前不断申请上锁,然后对公共资源count++,然后释放锁的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 $./x86.py -p flag.s ... Thread 0 Thread 1 1000 mov flag, %ax 1001 test $0 , %ax 1002 jne .acquire 1003 mov $1 , flag 1004 mov count, %ax 1005 add $1 , %ax 1006 mov %ax, count 1007 mov $0 , flag 1008 sub $1 , %bx 1009 test $0 , %bx 1010 jgt .top 1011 halt ----- Halt;Switch ----- ----- Halt;Switch ----- 1000 mov flag, %ax 1001 test $0 , %ax 1002 jne .acquire 1003 mov $1 , flag 1004 mov count, %ax 1005 add $1 , %ax 1006 mov %ax, count 1007 mov $0 , flag 1008 sub $1 , %bx 1009 test $0 , %bx 1010 jgt .top 1011 halt
和上面的26的作业类似,在中断时间片较短的时候,两个线程都能够完成各自的工作。这个时候,count能够获得两个线程的累加工作,并获得确定的答案。既能够获得某个线程两倍的累加量。
2. 上面其实已经解释了。答案是会的,能够按照预期工作。我们可以详细跟踪各个变量和寄存器的值看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 $./x86.py -p flag.s -R ax,bx -M flag,count -c ... flag count ax bx Thread 0 Thread 1 0 0 0 0 0 0 0 0 1000 mov flag, %ax 0 0 0 0 1001 test $0 , %ax 0 0 0 0 1002 jne .acquire 1 0 0 0 1003 mov $1 , flag 1 0 0 0 1004 mov count, %ax 1 0 1 0 1005 add $1 , %ax 1 1 1 0 1006 mov %ax, count 0 1 1 0 1007 mov $0 , flag 0 1 1 -1 1008 sub $1 , %bx 0 1 1 -1 1009 test $0 , %bx 0 1 1 -1 1010 jgt .top 0 1 1 -1 1011 halt 0 1 0 0 ----- Halt;Switch ----- ----- Halt;Switch ----- 0 1 0 0 1000 mov flag, %ax 0 1 0 0 1001 test $0 , %ax 0 1 0 0 1002 jne .acquire 1 1 0 0 1003 mov $1 , flag 1 1 1 0 1004 mov count, %ax 1 1 2 0 1005 add $1 , %ax 1 2 2 0 1006 mov %ax, count 0 2 2 0 1007 mov $0 , flag 0 2 2 -1 1008 sub $1 , %bx 0 2 2 -1 1009 test $0 , %bx 0 2 2 -1 1010 jgt .top 0 2 2 -1 1011 halt
可以看到两个线程的循环变量寄存器都是bx,它们都是1,说明可以各自累加一次。count的初始值是0,所以最终各自累加一次,可以看到最后count的值恰好是2,证明了可以按照预期工作。
3. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 $./x86.py -p flag.s -R ax,bx -M flag,count -c -a bx=2,bx=2 ... flag count ax bx Thread 0 Thread 1 0 0 0 2 0 0 0 2 1000 mov flag, %ax 0 0 0 2 1001 test $0 , %ax 0 0 0 2 1002 jne .acquire 1 0 0 2 1003 mov $1 , flag 1 0 0 2 1004 mov count, %ax 1 0 1 2 1005 add $1 , %ax 1 1 1 2 1006 mov %ax, count 0 1 1 2 1007 mov $0 , flag 0 1 1 1 1008 sub $1 , %bx 0 1 1 1 1009 test $0 , %bx 0 1 1 1 1010 jgt .top 0 1 0 1 1000 mov flag, %ax 0 1 0 1 1001 test $0 , %ax 0 1 0 1 1002 jne .acquire 1 1 0 1 1003 mov $1 , flag 1 1 1 1 1004 mov count, %ax 1 1 2 1 1005 add $1 , %ax 1 2 2 1 1006 mov %ax, count 0 2 2 1 1007 mov $0 , flag 0 2 2 0 1008 sub $1 , %bx 0 2 2 0 1009 test $0 , %bx 0 2 2 0 1010 jgt .top 0 2 2 0 1011 halt 0 2 0 2 ----- Halt;Switch ----- ----- Halt;Switch ----- 0 2 0 2 1000 mov flag, %ax 0 2 0 2 1001 test $0 , %ax 0 2 0 2 1002 jne .acquire 1 2 0 2 1003 mov $1 , flag 1 2 2 2 1004 mov count, %ax 1 2 3 2 1005 add $1 , %ax 1 3 3 2 1006 mov %ax, count 0 3 3 2 1007 mov $0 , flag 0 3 3 1 1008 sub $1 , %bx 0 3 3 1 1009 test $0 , %bx 0 3 3 1 1010 jgt .top 0 3 0 1 1000 mov flag, %ax 0 3 0 1 1001 test $0 , %ax 0 3 0 1 1002 jne .acquire 1 3 0 1 1003 mov $1 , flag 1 3 3 1 1004 mov count, %ax 1 3 4 1 1005 add $1 , %ax 1 4 4 1 1006 mov %ax, count 0 4 4 1 1007 mov $0 , flag 0 4 4 0 1008 sub $1 , %bx 0 4 4 0 1009 test $0 , %bx 0 4 4 0 1010 jgt .top 0 4 4 0 1011 halt
和前面的题目一样,实际就是两个线程分别进行两次累加,可以看到到目前为止,都能够正确完成累加。原因是中断切换线程执行的时候,两个线程都能够完成所有的累加,就不会出现存在竞态条件的情况。
4. 这里我让循环为50次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $./x86.py -p flag.s -R ax,bx -M flag,count -c -a bx=50,bx=50 -i 3 ... flag count ax bx Thread 0 Thread 1 0 0 0 2 0 0 0 2 1000 mov flag, %ax 0 0 0 2 1001 test $0 , %ax 0 0 0 2 1002 jne .acquire 1 0 0 2 1003 mov $1 , flag 1 0 0 2 1004 mov count, %ax 1 0 1 2 1005 add $1 , %ax 1 1 1 2 1006 mov %ax, count 0 1 1 2 1007 mov $0 , flag ... 1 57 57 1 1006 mov %ax, count 0 57 57 1 1007 mov $0 , flag 0 57 57 1 ------ Interrupt ------ ------ Interrupt ------ 0 57 57 0 1008 sub $1 , %bx 0 57 57 0 1009 test $0 , %bx 0 57 57 0 1010 jgt .top 0 57 57 0 ------ Interrupt ------ ------ Interrupt ------ 0 57 57 0 1011 halt
你能够看到两个线程循环50次,应该要能够累加100次,但是最后的结果是只累加了57次。此时我们说出现了不确定现象。
由于以flag作为锁,它的加锁和解锁本身没有原子性,所以并不能够起到保护共享资源的作用。所以随着bx增大,i减小,越容易产生不好的结果。反过来bx减小,i增大越趋向于产生确定的好的结果。
5. 现在我们研究另外一个文件,它是个使用硬件原语test-and-set的指令,详细看看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ cat test-and-set.s .var mutex .var count .main .top .acquire mov $1 , %ax xchg %ax, mutex test $0 , %ax jne .acquire mov count, %ax add $1 , %ax mov %ax, count mov $0 , mutex sub $1 , %bx test $0 , %bxjgt .top halt
同样针对上面的汇编代码我们写出c语言版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef char mutex_t ;mutex_t mutex;int count = 0 ;int i = n;int main () { do { while (test_and_set(&mutex, 0x1 ) != 0x0 ) ; count++; mutex = 0x0 ; i--; } while (i > 0 ); exit (1 ); }
其中获取锁部分:
1 2 3 4 5 6 7 8 9 while (test_and_set(&mutex, 0x1 ) != 0x0 ) ; => .acquire mov $1 , %ax xchg %ax, mutex # atomic swap of 1 and mutex test $0 , %ax # if we get 0 back: lock is free! jne .acquire # if not, try again
释放锁部分:
1 2 3 4 mutex = 0x0 ; => mov $0 , mutex
6. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ ./x86.py -p test-and-set.s -i 3 -a bx=50,bx=50 -M mutex,count -R ax,bx -c ... mutex count ax bx Thread 0 Thread 1 0 0 0 50 0 0 1 50 1000 mov $1 , %ax 1 0 0 50 1001 xchg %ax, mutex 1 0 0 50 1002 test $0 , %ax 1 0 0 50 ------ Interrupt ------ ------ Interrupt ------ 1 0 1 50 1000 mov $1 , %ax 1 0 1 50 1001 xchg %ax, mutex 1 0 1 50 1002 test $0 , %ax 1 0 0 50 ------ Interrupt ------ ------ Interrupt ------ ... 0 100 100 0 1008 sub $1 , %bx 0 100 100 0 ------ Interrupt ------ ------ Interrupt ------ 0 100 100 0 1009 test $0 , %bx 0 100 100 0 1010 jgt .top 0 100 100 0 1011 halt
可以看到在这种test-and-set的硬件原语支持下,能够保证原子性。所以最后计算的结果能够满足预期。但是可以从上面的代码中的看出,虽然保证了加锁的原子性,进而控制了了每次只能有一个线程在临界区。但是,由于当线程没有抢占到锁,就会在while中自旋等待,倘若拥有锁定的线程迟迟不释放锁,其他大量的线程就可能都处于自选等待的状态。而如果线程间调度采用的是类似轮转这样的算法,那么就会有大量的CPU资源用来自选。这种自选显然不是我们想要的,因此由于分时共享CPU的存在,CPU的使用率虽然比较高,但是做的有用功却不是很高,大部分时间在做自选等待。
现在考虑如何量化这样的CPU使用率的描述。就比如上面的示例代码两个线程一共做了100次累加,每次累加只有下面3条指令是经行累加的
1 2 3 4 # critical section mov count, %ax # get the value at the address add $1, %ax # increment it mov %ax, count # store it back
因此也就只有3*100 = 300条指令做有用功,剩下的通通是无用功。可以统计上面的计算共有2010行。由于整个计算过程CPU都处于工作状态。因此使用率100%。但是有效使用率仅有300/2010 = 14.93%
7. 首先我们需要通过增加-P属性来规定执行的顺序。例如:-P 1100111000111000111000就会依次按照t1,t1,t0,t0,t1,…,t0,t0,t0的顺序执行线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ ./x86.py -p test-and-set.s -i 10 -R ax,bx -M mutex,count -a bx=5 -P 1100111000111000111000 -c ... mutex count ax bx Thread 0 Thread 1 0 0 0 5 0 0 1 5 1000 mov $1 , %ax 1 0 0 5 1001 xchg %ax, mutex 1 0 0 5 ------ Interrupt ------ ------ Interrupt ------ 1 0 1 5 1000 mov $1 , %ax 1 0 1 5 1001 xchg %ax, mutex 1 0 0 5 ------ Interrupt ------ ------ Interrupt ------ 1 0 0 5 1002 test $0 , %ax 1 0 0 5 1003 jne .acquire ... 1 10 10 1 1006 mov %ax, count 0 10 10 1 1007 mov $0 , mutex 0 10 10 0 1008 sub $1 , %bx 0 10 10 0 1009 test $0 , %bx 0 10 10 0 1010 jgt .top 0 10 10 0 1011 halt
可以看到最后结果是正确的,由于上面的获取锁过程是具有原子性的,也就是说每一次只能有一个线程执行成功(成功把flag从0变成1)获得锁。因此也就保证了正确性。
第30章 由于第30章中文版课本上没有题目,因此在这里放出英文课本原题。
1.
这个题目要我们专注于文件main-two-cvs-while.c。首先需要先了解代码的含义,理解代码运行会发生什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #include <ctype.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <assert.h> #include <pthread.h> #include <sys/time.h> #include <string.h> #include "common.h" #include "common_threads.h" #include "pc-header.h" pthread_cond_t empty = PTHREAD_COND_INITIALIZER;pthread_cond_t fill = PTHREAD_COND_INITIALIZER;pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;#include "main-header.h" void do_fill (int value) { ensure(buffer[fill_ptr] == EMPTY, "error: tried to fill a non-empty buffer" ); buffer[fill_ptr] = value; fill_ptr = (fill_ptr + 1 ) % max; num_full++; } int do_get () { int tmp = buffer[use_ptr]; ensure(tmp != EMPTY, "error: tried to get an empty buffer" ); buffer[use_ptr] = EMPTY; use_ptr = (use_ptr + 1 ) % max; num_full--; return tmp; } void *producer (void *arg) { int id = (int ) arg; int base = id * loops; int i; for (i = 0 ; i < loops; i++) { p0; Mutex_lock(&m); p1; while (num_full == max) { p2; Cond_wait(&empty, &m); p3; } do_fill(base + i); p4; Cond_signal(&fill); p5; Mutex_unlock(&m); p6; } return NULL ; } void *consumer (void *arg) { int id = (int ) arg; int tmp = 0 ; int consumed_count = 0 ; while (tmp != END_OF_STREAM) { c0; Mutex_lock(&m); c1; while (num_full == 0 ) { c2; Cond_wait(&fill, &m); c3; } tmp = do_get(); c4; Cond_signal(&empty); c5; Mutex_unlock(&m); c6; consumed_count++; } return (void *) (long long ) (consumed_count - 1 ); } pthread_cond_t *fill_cv = &fill;pthread_cond_t *empty_cv = ∅#include "main-common.c"
对上面的代码我们做出了解析,如注释所示。我们的生产者会调用do_fill进行生产活动,一次只生产一个货物到空货架上。消费者会调用do_get获取货物,一次只获得一个商品。货架是一个数组,上面依次存取商品,由fill_ptr指明放入位置,由use_ptr知名从哪个位置取商品。
2.
运行一个生产者一个消费者程序,然后让生产者生产一些特定的值。一开始我们只是使用一个长度大小只有1的buffer,然后慢慢增长它。当货架增大,程序代码会做和行为?你认为num_full会随着buffer的容量变大有什么不同(例如可以设成-l 100),当你改变消费者字符串,从默认的不睡眠到-C 0,0,0,0,0,0,1会发生什么?
这是一个项目程序,我们应该先编译他们:
编译完成生成了几个可执行的程序,现在我们让buffer长度为1,然后仅仅看看一个生产者和一个消费者的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv $ ./main-two-cvs-while -p 1 -c1 -m 1 -v NF P0 C0 0 [*--- ] c0 0 [*--- ] p0 0 [*--- ] c1 0 [*--- ] c2 0 [*--- ] p1 1 [* 0 ] p4 1 [* 0 ] p5 1 [* 0 ] p6 1 [* 0 ] c3 0 [*--- ] c4 0 [*--- ] c5 1 [*EOS ] [main: added end-of-stream marker] 1 [*EOS ] c6 1 [*EOS ] c0 1 [*EOS ] c1 0 [*--- ] c4 0 [*--- ] c5 0 [*--- ] c6 Consumer consumption: C0 -> 1
上面的数码做了一件事:[]中放的是buffer的内容,再往左是buffer的full_num。然后是对应的生产者消费者执行的步骤。(具体请见上面c代码)首先消费者执行c0,然后是消费者执行p0。然后消费者执行c1获取锁。然后while判断货架为空准备进入等待并释放锁。然后生产者获取锁,while判断货架为空跳过等待进行生产,然后唤醒消费者并释放锁。然后消费者苏醒获取锁,进行消费。此时以达到生产线最后元素(EOS)。然后消费者退出循环并返回。最后我们可以看到消费者C0消费了一个商品。上面过程没有出现什么问题。
接下来我们增大buffer尺寸。比如加到10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv $ ./main-two-cvs-while -p 1 -c1 -m 10 -v NF P0 C0 0 [*--- --- --- --- --- --- --- --- --- --- ] c0 0 [*--- --- --- --- --- --- --- --- --- --- ] p0 0 [*--- --- --- --- --- --- --- --- --- --- ] p1 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p4 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p5 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p6 1 [u 0 f--- --- --- --- --- --- --- --- --- ] c1 0 [ --- *--- --- --- --- --- --- --- --- --- ] c4 0 [ --- *--- --- --- --- --- --- --- --- --- ] c5 1 [ --- uEOS f--- --- --- --- --- --- --- --- ] [main: added end-of-stream marker] 1 [ --- uEOS f--- --- --- --- --- --- --- --- ] c6 1 [ --- uEOS f--- --- --- --- --- --- --- --- ] c0 1 [ --- uEOS f--- --- --- --- --- --- --- --- ] c1 0 [ --- --- *--- --- --- --- --- --- --- --- ] c4 0 [ --- --- *--- --- --- --- --- --- --- --- ] c5 0 [ --- --- *--- --- --- --- --- --- --- --- ] c6 Consumer consumption: C0 -> 1
可以看到-l不发生变化,实际上和前面差不多,都没有什么问题。
然后我们现在增加生产次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv$ ./main-two-cvs-while -p 1 -c1 -m 10 -l 100 -v NF P0 C0 0 [*--- --- --- --- --- --- --- --- --- --- ] p0 0 [*--- --- --- --- --- --- --- --- --- --- ] c0 0 [*--- --- --- --- --- --- --- --- --- --- ] p1 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p4 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p5 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p6 ... 1 [f--- --- --- --- --- --- --- --- --- u 99 ] p5 1 [f--- --- --- --- --- --- --- --- --- u 99 ] p6 1 [f--- --- --- --- --- --- --- --- --- u 99 ] c1 0 [*--- --- --- --- --- --- --- --- --- --- ] c4 0 [*--- --- --- --- --- --- --- --- --- --- ] c5 1 [uEOS f--- --- --- --- --- --- --- --- --- ] [main: added end-of-stream marker] 1 [uEOS f--- --- --- --- --- --- --- --- --- ] c6 1 [uEOS f--- --- --- --- --- --- --- --- --- ] c0 1 [uEOS f--- --- --- --- --- --- --- --- --- ] c1 0 [ --- *--- --- --- --- --- --- --- --- --- ] c4 0 [ --- *--- --- --- --- --- --- --- --- --- ] c5 0 [ --- *--- --- --- --- --- --- --- --- --- ] c6 Consumer consumption: C0 -> 100
可以看到消费者都能够正常获得商品。
现在改变消费者睡眠字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv$ ./main-two-cvs-while -p 1 -c1 -m 10 -l 100 -v NF P0 C0 0 [*--- --- --- --- --- --- --- --- --- --- ] p0 0 [*--- --- --- --- --- --- --- --- --- --- ] c0 0 [*--- --- --- --- --- --- --- --- --- --- ] p1 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p4 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p5 1 [u 0 f--- --- --- --- --- --- --- --- --- ] p6 1 [u 0 f--- --- --- --- --- --- --- --- --- ] c1 0 [ --- *--- --- --- --- --- --- --- --- --- ] c4 0 [ --- *--- --- --- --- --- --- --- --- --- ] p0 0 [ --- *--- --- --- --- --- --- --- --- --- ] c5 0 [ --- *--- --- --- --- --- --- --- --- --- ] c6 0 [ --- *--- --- --- --- --- --- --- --- --- ] p1 0 [ --- *--- --- --- --- --- --- --- --- --- ] c0 1 [ --- u 1 f--- --- --- --- --- --- --- --- ] p4 1 [ --- u 1 f--- --- --- --- --- --- --- --- ] p5 ... 0 [ --- --- --- --- --- *--- --- --- --- --- ] p1 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] p4 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] c0 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] p5 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] p6 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] c1 1 [ --- --- --- --- --- u 25 f--- --- --- --- ] p0 0 [ --- --- --- --- --- --- *--- --- --- --- ] c4 0 [ --- --- --- --- --- --- *--- --- --- --- ] c5 0 [ --- --- --- --- --- --- *--- --- --- --- ] c6 0 [ --- --- --- --- --- --- *--- --- --- --- ] p1 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] p4 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] c0 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] p5 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] p6 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] p0 1 [ --- --- --- --- --- --- u 26 f--- --- --- ] c1 0 [ --- --- --- --- --- --- --- *--- --- --- ] c4 0 [ --- --- --- --- --- --- --- *--- --- --- ] c5 0 [ --- --- --- --- --- --- --- *--- --- --- ] c6 0 [ --- --- --- --- --- --- --- *--- --- --- ] p1 0 [ --- --- --- --- --- --- --- *--- --- --- ] c0 1 [ --- --- --- --- --- --- --- u 27 f--- --- ] p4 1 [ --- --- --- --- --- --- --- u 27 f--- --- ] p5 1 [ --- --- --- --- --- --- --- u 27 f--- --- ] p6 1 [ --- --- --- --- --- --- --- u 27 f--- --- ] c1 1 [ --- --- --- --- --- --- --- u 27 f--- --- ] p0 0 [ --- --- --- --- --- --- --- --- *--- --- ] c4 ... 9 [f--- u 1 2 3 4 5 6 7 8 9 ] p0 9 [f--- u 1 2 3 4 5 6 7 8 9 ] p1 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p4 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p5 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p6 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p0 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p1 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] p2 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] c0 10 [ 10 * 1 2 3 4 5 6 7 8 9 ] c1 9 [ 10 f--- u 2 3 4 5 6 7 8 9 ] c4 9 [ 10 f--- u 2 3 4 5 6 7 8 9 ] c5 9 [ 10 f--- u 2 3 4 5 6 7 8 9 ] c6 9 [ 10 f--- u 2 3 4 5 6 7 8 9 ] p3 ... 1 [uEOS f--- --- --- --- --- --- --- --- --- ] c0 1 [uEOS f--- --- --- --- --- --- --- --- --- ] c1 0 [ --- *--- --- --- --- --- --- --- --- --- ] c4 0 [ --- *--- --- --- --- --- --- --- --- --- ] c5 0 [ --- *--- --- --- --- --- --- --- --- --- ] c6 Consumer consumption: C0 -> 100
看到上面的代码,生产f总是在使用u之前。
同时消费者总是等到缓冲区满了才开始消费。然后消费一个就通知生产者生产直到生产完毕。
此时一切生产消费活动都处于正常状态。
4.
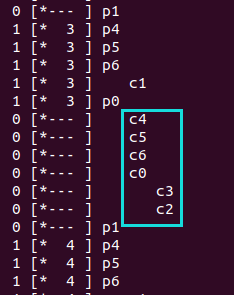
如果只有一个生产者,三个消费者,只有一个单一入口的buffer,每个消费者在c3指令执行的时候入睡要一秒钟(-C 0,0,0,1,0,0,0)
我们输入指令看看情况发生了什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv $ ./main-two-cvs-while -p 1 -c 3 -m 1 -C 0,0,0,1,0,0,0:0,0,0,1,0,0,0:0,0,0,1,0,0,0 -l 10 -v -t NF P0 C0 C1 C2 0 [*--- ] c0 0 [*--- ] p0 0 [*--- ] c0 0 [*--- ] c0 0 [*--- ] c1 0 [*--- ] c2 0 [*--- ] p1 1 [* 0 ] p4 1 [* 0 ] p5 1 [* 0 ] p6 1 [* 0 ] c1 ... Consumer consumption: C0 -> 0 C1 -> 10 C2 -> 0 Total time: 13.07 seconds
1 2 3 4 5 6 7 ... Consumer consumption: C0 -> 9 C1 -> 0 C2 -> 1 Total time: 12.08 seconds
不同次运行同样的命令,每次的运行时间不一致。但至少10s,因为消费者会取出10个数据。每取一个都会有1s的休眠。
可以看到上面的代码能够保证生产10个消费10个,但是存在消费者会被饿死的情况。
8.
现在看看main-one-cv-while.c,现在我们要写一个睡眠字符串,在只有一个生产者和一个消费者和一个缓冲区只有1大小的情况下产生问题。
一个生产者一个消费者不会产生什么问题,因为通信的只有生产者和消费者。但是如果出现两个生产者或者两个消费者的时候,一个条件变量就会不清楚通知的是生产者还是消费者。
9.
这个问题是课本257页表格表示的只有一个条件变量的问题。因为条件变量只有一个,所以所以可能存在一个消费者消费完试图唤醒生产者,但是不是唤醒生产者而是唤醒另外一个消费者,最终造成发出信号的消费者睡着,生产者没有醒过来,另外一个消费者醒过来发现没有东西消费,然后又睡着的情况。最终三个人都睡着了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 for (i = 0 ; i < loops; i++) { p0; Mutex_lock(&m); p1; while (num_full == max) { p2; Cond_wait(&empty, &m); p3; } do_fill(base + i); p4; Cond_signal(&fill); p5; Mutex_unlock(&m); p6; } while (tmp != END_OF_STREAM) { c0; Mutex_lock(&m); c1; while (num_full == 0 ) { c2; Cond_wait(&fill, &m); c3; } tmp = do_get(); c4; Cond_signal(&empty); c5; Mutex_unlock(&m); c6;
我们可以看到p3是进行苏醒的,我们让它睡久一点,就能够触发问题了。比如这里我们让他睡五秒。
得到结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv $ ./main-one-cv-while -m 1 -l 5 -c 2 -p 1 -P 0,0,0,10,0,0,0 -v -t NF P0 C0 C1 0 [*--- ] c0 0 [*--- ] p0 0 [*--- ] c0 0 [*--- ] p1 1 [* 0 ] p4 ... 0 [*--- ] c5 0 [*--- ] c6 Consumer consumption: C0 -> 5 C1 -> 0
可以看到上面蓝色框框的部分C0消费完,不是唤醒P0,而是唤醒C1。
但是由于它编写的调度器总会在所有程序睡眠后调用生产者进行生产。所以可以看到蓝色框框下面又出现了生产者进行生产。但是实际上如果它的调度程序不这么智慧的话,三个线程都会进入睡眠状态。
10.
这个题目要我们运行main-two-cvs-if.c文件。这个文件对等待函数是用if,也就是说仅仅进行一次判定。要我们考虑一个生产者一个消费者的情况,然后增加消费者的数量。试图产生问题。
我们说一个生产者一个消费者是不会有任何问题的。
但是如果有一个消费者或者以上,那么问题就出现了。这个问题其实就是书本255页介绍的问题。就是说只是进行一次等待判断,但是在两个消费者的时候,可能一个消费者判断有货物可取,然后再在它取之前发生中断,然后另外一个消费者也看到了这个货物,然后它一口气取完了。然后前面一个消费者还蒙在鼓里,以为自己还有货物,实际上已经没有货物了。
所以我们在其中一个消费者的去货物之前让它睡久一点就好,可以看到到c4是去货物所以试着构造这样的字符串
1 -C 0,0,0,0,5,0,0:0,0,0,0,0,0,0
执行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 puitar@ubuntu:~/Desktop/ostep-homework/threads-cv $ ./main-two-cvs-if -m 1 -l 5 -c 2 -p 1 -C 0,0,0,0,5,0,0:0,0,0,0,0,0,0 -v -t NF P0 C0 C1 0 [*--- ] c0 0 [*--- ] p0 0 [*--- ] c1 0 [*--- ] c0 0 [*--- ] c2 0 [*--- ] p1 1 [* 0 ] p4 1 [* 0 ] p5 1 [* 0 ] p6 1 [* 0 ] c1 1 [* 0 ] p0 0 [*--- ] c4 0 [*--- ] c5 0 [*--- ] c6 0 [*--- ] c3 0 [*--- ] c0 error: tried to get an empty buffer
我们很容易就出发了这个错误。问题就是消费者2消费的速度明显更快,然后在15行的地方很快消费了货物,但是消费者1在c3的地方苏醒过来,没有再次判断是不是“假唤醒”(课本260页提示,所谓假唤醒就是唤醒你,但是你但是你没有货物),然后它认为它是有货物取得,所以在20行本来应该是消费者1进行取货c4操作,但是没有货物引起报错。
11.
我们最后考察一个这样的程序main-two-cvs-while-extra-unlock.c。考察它会发生什么样的问题。如果你在放一个货物或者取一个货物之前就释放锁会发生什么。你可依托这一点给出一个睡眠字符串吗?分析发生了什么不好的事情。
和前面的代码不同的地方就在于它的生产者和消费者函数,是在释放锁之后才取资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 void do_fill (int value) { ensure(buffer[fill_ptr] == EMPTY, "error: tried to fill a non-empty buffer" ); buffer[fill_ptr] = value; fill_ptr = (fill_ptr + 1 ) % max; num_full++; } int do_get () { int tmp = buffer[use_ptr]; ensure(tmp != EMPTY, "error: tried to get an empty buffer" ); buffer[use_ptr] = EMPTY; use_ptr = (use_ptr + 1 ) % max; num_full--; return tmp; } void *producer (void *arg) { int id = (int ) arg; int base = id * loops; int i; for (i = 0 ; i < loops; i++) { p0; Mutex_lock(&m); p1; while (num_full == max) { p2; Cond_wait(&empty, &m); p3; } Mutex_unlock(&m); do_fill(base + i); p4; Mutex_lock(&m); Cond_signal(&fill); p5; Mutex_unlock(&m); p6; } return NULL ; } void *consumer (void *arg) { int id = (int ) arg; int tmp = 0 ; int consumed_count = 0 ; while (tmp != END_OF_STREAM) { c0; Mutex_lock(&m); c1; while (num_full == 0 ) { c2; Cond_wait(&fill, &m); c3; } Mutex_unlock(&m); tmp = do_get(); c4; Mutex_lock(&m); Cond_signal(&empty); c5; Mutex_unlock(&m); c6; consumed_count++; } return (void *) (long long ) (consumed_count - 1 ); }
我们的公共资源就是buffer,但是把do_fill和do_get放在锁的外面,这个锁就不起作用了。
如果只有一个消费者和生产者由于条件变量和full_num的共同作用,能够保证生产时消费者在睡,消费时生产者在睡。但是,如果有多个生产者和多个消费者的情况下,由于只能保证一个生产者和一个消费者互斥。所以其他的就可以对公共资源进行改写。比如在一个消费者取货物之前可能另外一个生产者覆盖了这个货物。
比如这里的2是被消费者0消费了,但是它很可能在c4消费之前,他消费的东西就被别的消费者覆盖了。
我们可以让c4执行慢一点,刚好让别的生产者抢占锁
1 -C 0,0,0,0,5,0,0:0,0,0,0,5,0,0
第31章 1.
第一题要我们实现fork/join问题,要求自己写一个线程fork-join的程序,你要工作的是作业目录下的fork-join.c文件。同时在child添加sleep(1)试着确定他的正确性。
和课本266页一致,但是要注意几点:
child释放post信号量应该在孩子已经工作完的情况下创建完子线程之后,主线程等待子线程完毕
下面书写代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <stdio.h> #include <unistd.h> #include <pthread.h> #include "common_threads.h" sem_t s; void *child (void *arg) { printf ("child\n" ); sleep(1 ); Sem_post(&s) return NULL ; } int main (int argc, char *argv[]) { pthread_t p; printf ("parent: begin\n" ); Sem_init(&s, 0 ) Pthread_create(&p, NULL , child, NULL ); Sem_wait(&s) printf ("parent: end\n" ); return 0 ; }
关于上述代码有几点说明:
1 2 3 #define Sem_init(sem, value) assert(sem_init(sem, 0, value) == 0); #define Sem_wait(sem) assert(sem_wait(sem) == 0); #define Sem_post(sem) assert(sem_post(sem) == 0);
运行编译时,需要加上-pthread的tag运行结果如下
当加入sleep(1)的时候同样运行正确,验证代码正确性。
2.
现在看看rendezvous问题。这个问题表述如下:你有两个线程,每一个线程都将要进入到rendezvous点执行代码。每一部分都不会在其他线程进入这个代码的时候退出,而是等待。思考使用两个信号量实现这个过程。详见rendezvous.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <stdio.h> #include <unistd.h> #include "common_threads.h" sem_t s1, s2;void *child_1 (void *arg) { printf ("child 1: before\n" ); Sem_wait(&s1) printf ("child 1: after\n" ); Sem_post(&s2) return NULL ; } void *child_2 (void *arg) { sleep(1 ); printf ("child 2: before\n" ); Sem_post(&s1) Sem_wait(&s2) printf ("child 2: after\n" ); return NULL ; } int main (int argc, char *argv[]) { pthread_t p1, p2; printf ("parent: begin\n" ); Sem_init(&s1, 0 ) Sem_init(&s2, 0 ) Pthread_create(&p1, NULL , child_1, NULL ); Pthread_create(&p2, NULL , child_2, NULL ); Pthread_join(p1, NULL ); Pthread_join(p2, NULL ); printf ("parent: end\n" ); return 0 ; }
一点说明:这里把信号量作为条件变量使用,当条件变量发生变化,可以继续执行。可以看到如果child1先工作,它打印完它的before信息之后,会等待s1的讯息。然后child2输出它的before信息,然后它唤醒child1,然后自己进入睡眠等待child1打印它的after信息,然后child1打印完会唤醒child2,child2打印after讯息。最终实现次序打印。
结果如下:
4.
这道题要求我们自己编写读写锁的详细代码。在这里我们不需要考虑饿死的问题。
代码如下
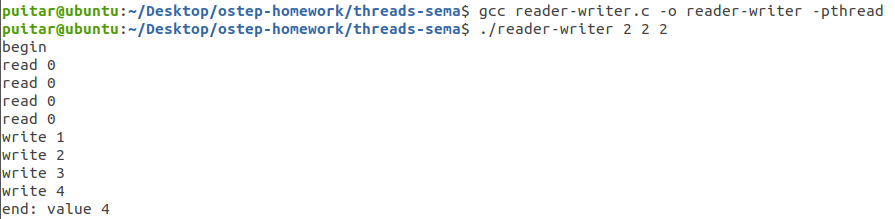
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include "common_threads.h" typedef struct __rwlock_t { sem_t lock; sem_t writelock; int readers; } rwlock_t ; void rwlock_init (rwlock_t *rw) { rw->readers = 0 ; Sem_init(&rw->lock, 1 ) Sem_init(&rw->writelock, 1 ) } void rwlock_acquire_readlock (rwlock_t *rw) { Sem_wait(&rw->lock) rw->readers++; if (rw->readers == 1 ) Sem_wait(&rw->writelock) Sem_post(&rw->lock) } void rwlock_release_readlock (rwlock_t *rw) { Sem_wait(&rw->lock) rw->readers--; if (rw->readers == 0 ) Sem_post(&rw->writelock) Sem_post(&rw->lock) } void rwlock_acquire_writelock (rwlock_t *rw) { Sem_wait(&rw->writelock) } void rwlock_release_writelock (rwlock_t *rw) { Sem_post(&rw->writelock) } int loops;int value = 0 ;rwlock_t lock;void *reader (void *arg) { int i; for (i = 0 ; i < loops; i++) { rwlock_acquire_readlock(&lock); sleep(1 ); printf ("read %d\n" , value); rwlock_release_readlock(&lock); } return NULL ; } void *writer (void *arg) { int i; for (i = 0 ; i < loops; i++) { rwlock_acquire_writelock(&lock); value++; printf ("write %d\n" , value); rwlock_release_writelock(&lock); } return NULL ; } int main (int argc, char *argv[]) { assert(argc == 4 ); int num_readers = atoi(argv[1 ]); int num_writers = atoi(argv[2 ]); loops = atoi(argv[3 ]); pthread_t pr[num_readers], pw[num_writers]; rwlock_init(&lock); printf ("begin\n" ); int i; for (i = 0 ; i < num_readers; i++) Pthread_create(&pr[i], NULL , reader, NULL ); for (i = 0 ; i < num_writers; i++) Pthread_create(&pw[i], NULL , writer, NULL ); for (i = 0 ; i < num_readers; i++) Pthread_join(pr[i], NULL ); for (i = 0 ; i < num_writers; i++) Pthread_join(pw[i], NULL ); printf ("end: value %d\n" , value); return 0 ; }
运行结果如下
存在读者饿死写着的问题。看到上面的实验结果显示只有读者全部读完了才开始写。根据代码我们也可以看出来。第一个读者获取写锁,所以任何写者都不可以写,而在第一个读者获得写锁后,其他的读者是可以获得读锁的。一旦某一个读者抢到了写锁,其他的读者都会蜂拥而入(它们不受任何阻碍)然后执行读操作。而写者呢?它们很不幸,如果它们没有任何一个读者快抢到writelock,则它们不能够执行写,因为writelock还在第一个读者手上(writelock移交到最后一个读者手上了才释放),所以这些读者只能够等待几乎所有读者读完才能够进行写操作。同时还要保证在它们被最后一个读者唤醒之后没有其他读者和他们竞争,才能够安稳进行写操作。
5.
现在我们要写一个没有上面描述到的饥饿问题的程序。实际上我们需要做到的是:如何能够在有写者等待的时候,避免有更多的读者进入并持有锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include "common_threads.h" typedef struct __rwlock_t { sem_t lock; sem_t writelock; int readers; int writers; } rwlock_t ; void rwlock_init (rwlock_t *rw) { rw->readers = 0 ; rw->writers = 0 ; Sem_init(&rw->lock, 1 ) Sem_init(&rw->writelock, 1 ) } void rwlock_acquire_readlock (rwlock_t *rw) { Sem_wait(&rw->lock) while (rw->writers > 0 ) ; rw->readers++; if (rw->readers == 1 ) Sem_wait(&rw->writelock) Sem_post(&rw->lock) } void rwlock_release_readlock (rwlock_t *rw) { Sem_wait(&rw->lock) rw->readers--; if (rw->readers == 0 ) Sem_post(&rw->writelock) Sem_post(&rw->lock) } void rwlock_acquire_writelock (rwlock_t *rw) { Sem_wait(&rw->lock) rw->writers++; Sem_post(&rw->lock) Sem_wait(&rw->writelock) Sem_wait(&rw->lock) rw->writers--; Sem_post(&rw->lock) } void rwlock_release_writelock (rwlock_t *rw) { Sem_post(&rw->writelock) }
这种策略实际上是一种写者优先的策略。由于读写锁的策略是针对多数读者少数写者的情况。这里我采用简单的自旋技术,让读者在申请锁之前总需要先判断一下是否有写者等待,如果有读者自选等待。然后在rwlock_acquire_writelock的代码中对writers的改写需要保证原子性,所以需要上锁。但是我们需要把锁的范围缩小到上面的仅对加减writers的操作上锁解锁。从第51行到第53行可能发生中断,使得尽管写者已经释放了锁,但是等待数目没有来得及减。但是此时所有读者仍然在等待减完才能抢占CPU。这一点在这里不用担心。
最后我们看一种夸张的情况,每一个读者在抢占锁之前都睡眠一秒钟。结果显示能够让写者先进行写操作。说明我们解决了饥饿的问题。
6.
现在要用信号量实现没有饥饿问题的互斥量也就是锁。
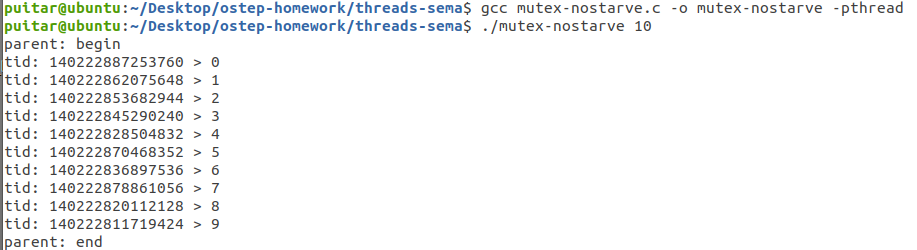
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <pthread.h> #include "common_threads.h" typedef struct __ns_mutex_t { int ticket; int turn; sem_t stic; sem_t stur; } ns_mutex_t ; void ns_mutex_init (ns_mutex_t *m) { Sem_init(&m->stic, 1 ) Sem_init(&m->stur, 1 ) m->ticket = 0 ; m->turn = 0 ; } void ns_mutex_acquire (ns_mutex_t *m) { Sem_wait(&m->stic) int myturn = m->ticket++; Sem_post(&m->stic) while (m->turn != myturn) ; } void ns_mutex_release (ns_mutex_t *m) { Sem_wait(&m->stur) m->turn++; Sem_post(&m->stur) } static int value = 0 ;ns_mutex_t lock;void *worker (void *arg) { ns_mutex_acquire(&lock); int tmp = value++; ns_mutex_release(&lock); printf ("tid: %ld > %d\n" , pthread_self(), tmp); return NULL ; } int main (int argc, char *argv[]) { assert(argc == 2 ); int num_workers = atoi(argv[1 ]); pthread_t pool[num_workers]; ns_mutex_init(&lock); printf ("parent: begin\n" ); for (int i = 0 ; i < num_workers; i++) Pthread_create(&pool[i], NULL , worker, NULL ); for (int i = 0 ; i < num_workers; i++) Pthread_join(pool[i], NULL ); printf ("parent: end\n" ); return 0 ; }
对于上面的代码,我们需要的是公平性,我们可以通过学习Mellor-Crummey和Michael Scott提出来的ticket和turn的机制(课本228页)写出代码如上。主要是用了这种turn的轮询机制。通过锁的全局ticket和turn,以及每个线程申请时的myturn来实现公平。课本上主要使用原语FetchAndAdd实现对lock->turn和lock->ticket原子操作,这里我们用信号量生成的锁来实现这种原语。其实上面带有FetchAndAdd的注释的地方的代码相当于下面
1 2 3 4 5 #define FetchAndAdd(sema) { Sem_wait(&m->stic) \ \ Sem_post(&m->stic) \ }
最终运行结果如下,我们可以清楚看到,每个线程都调度了,达到了相对的公平性。